Automated Function ID Database Generation in Ghidra on Windows
Function ID databases are the equivalent of IDA Pro’s FLIRT (Fast Library Identification and Recognition Technology). They allow analysts to build databases of function signatures that can later be applied to other binaries. But what does this actually mean?
During software reverse engineering, we often encounter binaries that lack symbol information. Without symbols, reverse engineering becomes significantly harder. Identifying function implementations based solely on assembly and generic labels (which are often just numbers or offsets) can be extremely time-consuming. While it's possible to go through each function manually, analyse its logic and rename it accordingly, this process takes a significant amount of time — something we’re usually short on.
In most cases, software uses libraries. These might be SOs (Shared Objects) on Unix-like systems or DLLs (Dynamic-Link Libraries) on Windows. Such libraries typically contain symbol names, making reverse engineering easier since you don't need to analyse what each function does. However, in some cases, libraries are statically linked and compiled directly into the binary. In those situations, the symbol information is often stripped out, and we’re left having to identify everything manually.
If the libraries are open source (FOSS FTW!), we can compare the source code with the decompiled or disassembled binary and match function implementations that way. Unfortunately, this can still be time-consuming and error-prone, especially if the compiler used aggressive optimization or reordered the code.
So far, the most effective way we've found to reduce workload and make our lives easier is by building a Function ID database in Ghidra and applying it to the decompiled code. Ghidra — like IDA Pro — can analyze functions and generate function signatures based on them. These signatures can be created using various function attributes, such as:
- Function name (which, as you know, is typically missing)
- Hash of the normalized function bytes
- Other metadata (e.g. size, prototype)
These signatures can be stored in databases that can later be applied to other binaries as well. Fortunately, we’re standing on the shoulders of giants — several scripts and guides are available for Linux that do most of the heavy lifting for us. For example, @0x6d696368 addressed this exact challenge by creating an excellent write-up and set of scripts to generate Function ID databases from static libraries on Linux.
In our case, however, this was only a partial help, as we were dealing with a Windows application that turned out to be using OpenSSL. The specific version was quickly identified within the code:
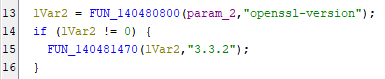
Therefore, the corresponding version of OpenSSL was downloaded and compiled on Windows for x64 (matching the target binary) as a static build. This process produced two .lib files, each containing a large number of .obj files. Since all .obj files must first be extracted, imported, and analysed before Function ID hashes can be generated, doing this manually would be extremely time-consuming. To streamline the process, we used @0x6d696368's Ghidra scripts to analyse and generate the Function ID database. Additionally, we wrote PowerShell scripts to extract the .obj files from the .lib archives and import them into a Ghidra project.
Extracting object files from the static library:
.\01Extract-LibContents.ps1 .\libssl_static.lib
Importing object files into a Ghidra project:
.\02Import-Ghidra.ps1 .libssl_static openssl-libssl C:UsersUSERDesktopghidra_11.3.2_PUBLIC
Generating function signatures (hashes) from the newly created project:
.\03Generate-FIDB.ps1 libcrypto_static openssl-libcrypto C:UsersUSERDesktopghidra_11.3.2_PUBLIC
As an example, here is how this function looked when decompiled before applying the signatures to the project:
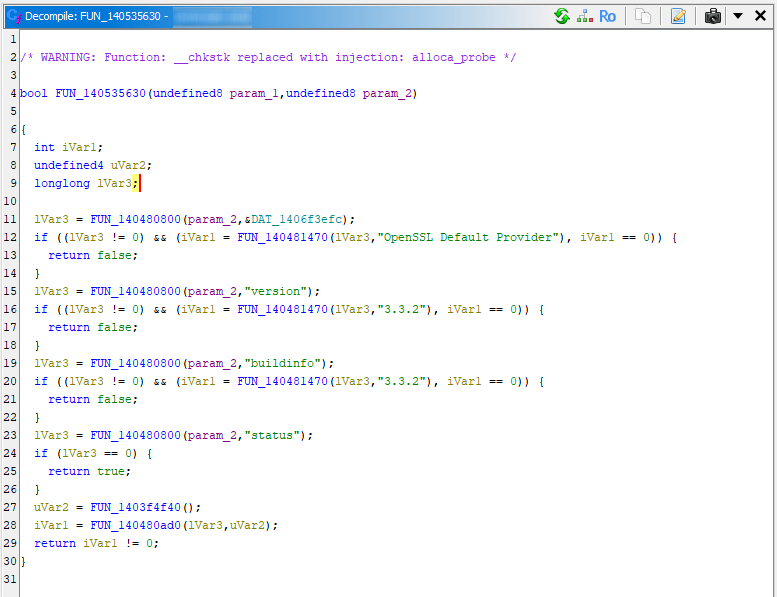
The same function after running the Function ID analysis with the correct databases attached (Analysis > One Shot > Function ID):
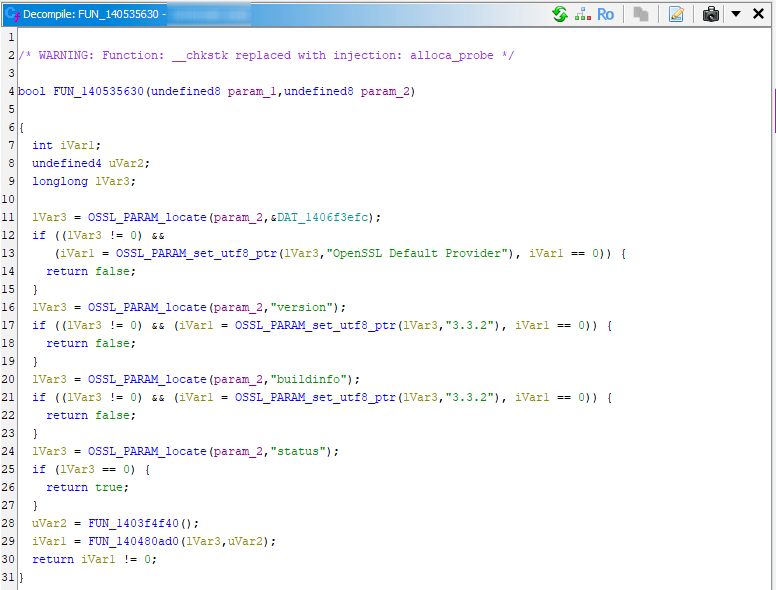
The difference is significant, even in this short function, where the majority of functions have been renamed and it is now clear which OpenSSL functions are used instead of just seeing numeric names. Additionally, the symbol tree is populated with a large number of OpenSSL functions utilized by this compiled application.
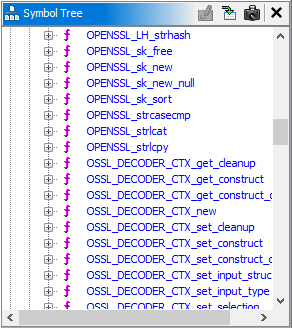
Now that the tooling has helped us prepare the binary by identifying and renaming functions, our research into potential security vulnerabilities can truly begin. With clear function names and better insights into the binary’s structure, we can focus our efforts on analysing critical code paths, spotting weaknesses and ultimately improving software security.
This automated Function ID database approach significantly reduces manual effort, speeds up reverse engineering, and enables more effective vulnerability discovery — especially when dealing with complex or stripped binaries.
The PowerShell scripts are available in our GitHub repository at the following link: https://github.com/mantrainfosec/SRE-FID_Generation_Windows
Contact
Contact Us
